
One of the most striking advances apparent at the Hamlyn Symposium on Medical Robotics was the wholesale adoption of advanced sensing technologies for providing superhuman abilities during surgery. This technology does have challenges and bottlenecks, chief among them the slow and expensive task of gathering source data that forces developers into a series of compromises. Countering this, however, are novel AI-based imaging approaches that can be used to increase resolution and make noisy data interpretable again.
Two impressive examples were proposed at Hamlyn. One was a super-resolution technique based on a generative method called pix2pix, while the other was a smoke reduction method based on CycleGAN. Both were met with robust responses from experts in the audience. The gist of their questioning – ‘How can surgeons have confidence in the information?’ – centred on the key point that such generative methods can ‘hallucinate’ detail not present in reality. To understand why this is the case, and to establish how it might be avoided, it’s necessary to explore the way that super-resolution techniques work.
A brief history of super-resolution
The information bottleneck is a fundamental limitation of any measurement system. For example, it’s not possible for a camera to capture the complete information in a scene, as the camera image is digitised. Typically, it is stored as brightness in three channels (RGB, 24bit) and with a particular resolution. Using a single frame, it is impossible to resolve detail below this pixel/bit resolution.
Super-resolution microscopy techniques attempt to circumvent this limitation by precisely moving the sample stage or objective, and by photographing the sample multiple times it captures sub-pixel information. Similar approaches are used in astronomy to remove atmospheric noise, capturing sequences of images over hours or days and using sub-pixel image registration to allow the images to be summed to a single blur-free high-resolution image.
It’s important to note that these de-noising and super-resolution approaches are related problems in that they are reconstructing lost information by supplementing the inadequate pixel information with additional information from tiny variations in new images.
The pix2pix and CycleGAN architectures referenced in the Hamlyn talks work differently. They use only a single frame as their input. In this case the additional information is being filled in or generated, usually from a context-appropriate training set (for example a thousand or so surgical videos). They work using conditional Generative Adversarial Networks (GANs), a technique that places competing neural networks in opposition.
During training, the ‘forger’ network aims to generate images of increasing fidelity from a low resolution ‘conditioning’ image such that an ‘investigator’ network can no longer tell the difference between the forgery and the high-resolution training dataset. This technique is effectively encoding typical image features to convincingly infill in a wide range of information, from distortion and noise to inadequate pixel information. When generating an output, the algorithm picks from these learned features to ‘paint in’ the detail.
Is it now becoming clear why the audience members were expressing concerns? Despite the highly realistic outputs, the generated high-resolution features are drawn from pre-learned information and aren’t guaranteed to be correct. Crucially, they could be hiding clinically relevant features.

Figure 1
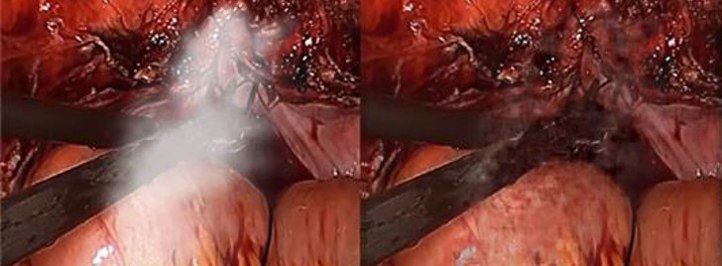
Figure 2

Figure 3
Cambridge Consultants, GAN-based SharpWave(TM) algorithm applied to (figure 1) add canvas and brushwork detail to increase image resolution (figure 2): remove smoke from surgical scenes (figure 3): significant noise reduction, note visible smoothing artefacts where information loss is severe – common to all single frame generative algorithms
This does not necessarily mean that they shouldn’t be used if they can be shown to confer a diagnostic benefit. It does, however, require careful human performance validation and testing with a wide range of potential edge cases to mitigate these risks. This in turn may require a disproportionate use of resources in identifying and testing all of the clinically relevant situations.
Going beyond generative systems
These generative methods are not the only way to address the information bottleneck. In addition to GAN-based systems, the team here at CC has been experimenting with hybrid systems that use deep learning to extract higher resolution information from multiple frames. Specifically, we take the multiple images from a laparoscopic surgical video to reconstruct high resolution images.
The key advantage of this multi-frame system is that all source information comes directly from the input video sequences, reducing artefacts that might mask clinically important features. We’re aiming to demonstrate our full system at an upcoming Hamlyn Symposium, but I have included some of our results below.
One early finding was that when developing super-resolution systems, they can offer lower than expected performance in operation when they have been developed using synthetic datasets. The digital down sampling approach commonly used, to generate the low-resolution paired images from high resolution originals, is not fully representative of the real world. In our system, we developed a novel (patented) training approach which more faithfully captures real world effects and human perception which has allowed our architecture to learn with a significant improvement in image quality (see Figure 4 C and D for a comparison).

Figure 4
(Figure 4) Deep learning based multi-frame super-resolution in combination with Cambridge Consultants IP significantly outperforms the previous state of the art in multi-frame super resolution.
There is a need for robust image enhancement algorithms that present clear, unambiguous diagnostic information to clinicians so that they can make accurate decisions. New high bandwidth sensors are allowing us to gather much more information than before and give surgeons superhuman abilities such as seeing through smoke or resolving ever finer detail.
We need techniques that increase data interpretability, validated to demonstrate that they are not masking clinically significant features. Due to the fidelity available to us via deep learning architectures, this means accurately representing every part of the signal chain (optics, CCD, debayering, tissue and so on) when generating data for training.
We are living at a very exciting time for advances in medicine. There is huge potential for AI to enhance clinical workflows, but we should be cautious. Information is lost at every interface, and it takes a multidisciplinary team and a systems-thinking approach to design surgical tools that communicate as much information as possible – and allow the best clinical decisions to be made. If you’d like to find out more about how our research team could help with your data problems, please get in touch.
Expert authors

Joe Corrigan
Joe is Chief Technology Officer at Cambridge Consultants and has grown the AI capability to become a world leading AI consultancy with the rigour to bring multiple class 2/3 products to market.


