
The risk of hallucinations remains a major barrier to deploying large language models (LLMs). In our paper, we introduce a method that can help mitigate that risk by detecting when a hallucination is likely.
In 2023, the Cambridge Dictionary chose ‘hallucinate’ as its Word of the Year. No wonder. As GenAI gathered steam worldwide, its propensity to generate answers that sound plausible but are factually wrong (i.e. ‘hallucinations’) was brought to the fore and much commented on. How do these happen and how can they be detected?
Hallucinations stem from gaps or biases in training data, and from training dynamics which incentivise confident guessing even when the model lacks knowledge. Just like people, LLMs find it difficult to say, ‘I don’t know’. This has damaging consequences, since lack of confidence in the accuracy of their outputs limits how LLMs can be used and deployed. This is especially true in a real-world application where an incorrect answer may cause harm.
Several methods have emerged to detect hallucinations. Methods based on single-model consistency entail repeatedly prompting an LLM with a given input and using consistency across the LLM’s responses to: 1) identify the most likely correct response and 2) assess the likelihood that the LLM is hallucinating (with more varied responses being typically indicative of hallucination).
While single-model consistency methods have achieved state-of-the-art (SOTA) results in hallucination detection and mitigation, they aren’t foolproof. If a model hallucinates in a consistent manner, they simply fail. For instance, they may give the same false answer when repeatedly asked a given question.
To address these shortcomings, our AI team experimented with a new approach.
Our approach to hallucination detection and mitigation
We started with the premise that multiple LLMs taken in combination are less likely to hallucinate in a consistent manner in response to a given input than a single LLM. In other words, consistency across responses from multiple LLMs ought to serve as a more reliable indicator of response trustworthiness.
We refer to this approach (illustrated below) as consortium consistency – a pair of related methods for detecting and mitigating hallucinations, which extend existing single-model consistency methods to use teams of multiple LLMs. These are:
- Consortium voting: Majority voting across responses from different LLMs to select a final response, thereby discarding any hallucinations which aren’t sufficiently prevalent to win the vote
- Consortium entropy: Measurement of how much the responses disagree, with higher disagreement meaning higher odds of hallucination, and high agreement meaning hallucination is unlikely
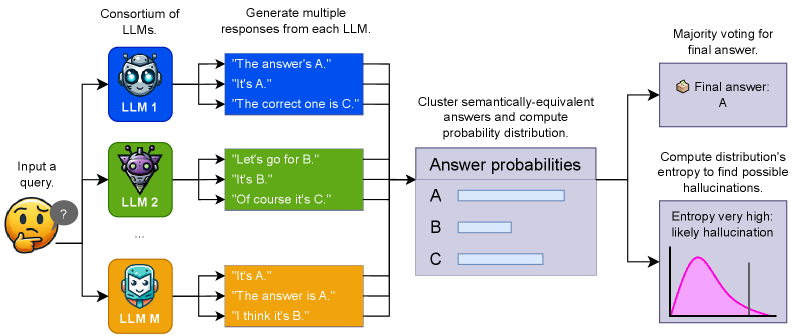
Illustration of consortium consistency (above). A given query is input to multiple LLMs, one or more responses are sampled from each model, semantically equivalent answers are clustered together, and the probability distribution of different answers is computed from these clustered samples. The distribution is used to calculate a final answer to the query, and an entropy score. Queries with higher entropy have less consistent responses and are hence more likely to contain hallucinations.
Our approach has several advantages: it is black-box (i.e. it doesn’t require access to the internal workings of the model) and zero-shot (i.e. doesn’t require any additional model training or data). This makes it straightforward to apply to any LLMs.
To determine under what circumstances it delivers the most benefit over existing single-model consistency methods, we experimented with different configurations. We applied it to many different LLM teams drawn from a pool of 15 LLMs of varying ability levels, and evaluated it on a suite of popular benchmark tasks (mathematical/technical reasoning and general/domain knowledge).
Evaluation and results
We identified simple heuristics for selecting which LLMs are likely to work well together:
- LLMs of similar ability levels tend to work better together than teams with a wider distribution of ability levels
- Teams of moderately strong LLMs tend to see more benefits from consortium consistency than teams of weaker LLMs (we haven’t yet tried with teams of very strong, current SOTA-level LLMs)
We found substantial performance gains compared to the single-model consistency approach with the above-described LLM team selection. Even against the hardest baseline (i.e. the best result when applying single-model consistency to each of the individual LLMs within a given team), our approach improves on each of our evaluation metrics for at least 92% of the LLM teams we evaluated.
Even teaming LLMs of widely disparate ability levels can sometimes outperform single-model consistency applied to just the strongest model in the team. This offers both stronger performance and cheaper inference costs: it’s typically more expensive to sample 20 responses from a single strong LLM than to sample 10 responses from that strong LLM and the other 10 from a much weaker LLM.
On top of this, the benefits of consortium consistency hold across a wide range of response budgets (from sampling two responses per input up to sampling 40).
Next steps for hallucination detection
Our paper opens up several avenues for further investigation:
- Experimenting with varying the diversity of evaluation tasks. We would expect the advantage of consortium consistency over single-model consistency to grow with diversity, and a single model to perform best on a narrow evaluation domain (if known)
- Applying consortium consistency to current SOTA LLMs to see how the performance of our method scales with LLM capabilities
- Experimenting with variants of the approach, e.g. weighting aggregation based on relative aptitudes of each LLM on a task domain to prevent weaker LLMs in the team from harming performance
While the risk of hallucinations presents a real danger to deploying LLMs in high-trust or mission-critical applications, our work shows that technical solutions can both detect and mitigate hallucinations, helping unlock the full potential of LLMs for these settings.
This paper has been accepted for presentation at the NeurIPS 2025 workshop on Reliable ML from Unreliable Data. Read more: Demian Till, John Smeaton, Peter Haubrick, Gouse Saheb, Florian Graef, and David Berman. Teaming LLMs to Detect and Mitigate Hallucinations. ArXiv, October 2025. URL: https://arxiv.org/html/2510.19507v2

Demian Till
Demian is a senior AI engineer with over 3 years experience delivering research-led machine learning solutions. His work has spanned defence, life sciences and AI safety and interpretability. He holds an MSc in Machine Learning from UCL, graduating with distinction and making the Dean’s List, and a first-class MSci in Computer Science from the University of Glasgow.


